
I recently came across a new [to me] approach, gradient boosting machines (specifically XGBoost), in the book Deep Learning with Python by François Chollet. Chollet mentions that XGBoost is the one shallow learning technique that a successful applied machine learner should be familiar with today, so I took his word for it and dove in to learn more.
I mostly wanted to write this article because I thought that others with some knowledge of machine learning also may have missed this topic as I did. I am by no means an expert on the topic and to be honest had trouble understanding some of the mechanics, however, I hope this article is a great primer to your exploration on the subject (list of great resources at the bottom too)!
Ensemble learning
So what is XGBoost and where does it fit in the world of ML? Gradient Boosting Machines fit into a category of ML called Ensemble Learning, which is a branch of ML methods that train and predict with many models at once to produce a single superior output. Think of it as planning out a few different routes to a single location you’ve never been to; as you use all of the routes, you begin to learn which traffic lights take long when and how the time of day impacts one route over the other, allowing you to craft the perfect route. You experimented with and combined a few different models to reach an optimal conclusion. Ensemble learning is similar!
Ensemble learning is broken up into three primary subsets:
-
- Bagging: Bootstrap Aggregation or Bagging has two distinct features which define its training and prediction. For training, it leverages a Bootstrap procedure to separate the training data into different random subsamples, which different iterations of the model used to train on. For prediction, a bagging classifier will use the prediction with the most votes from each model to produce its output and a bagging regression will take an average of all models to produce an output. Bagging is typically applied to high variance models such as Decision Trees and the Random Forest algorithm is a very close variation on bagging.
-
- Stacking: A Stacking model is a “meta-model” which leverages the outputs from a collection of many, typically significantly different, models as input features. For instance, this allows you to train a K-NN, Linear Regression, and Decision Tree with all of your training data, then take those outputs and merge them with a Logistical Regression. The idea is that this can reduce overfitting and improve accuracy.
- Boosting: Finally boosting! The core definition of boosting is a method that converts weak learners to strong learners and is typically applied to trees. More explicitly, a boosting algorithm adds iterations of the model sequentially, adjusting the weights of the weak-learners along the way. This reduces bias from the model and typically improves accuracy. Popular boosting algos are AdaBoost, Gradient Tree Boosting, and XGBoost, which we’ll focus on here.
XGBoost
eXtreme Gradient Boosting or XGBoost is a library of gradient boosting algorithms optimized for modern data science problems and tools. It leverages the techniques mentioned with boosting and comes wrapped in an easy to use library. Some of the major benefits of XGBoost are that its highly scalable/parallelizable, quick to execute, and typically outperforms other algorithms.
Throughout this section, we’ll explore XGBoost by predicting whether or not passengers survived on the Titanic. The full jupyter notebook used for this analysis can be found HERE.
I started by loading the Titanic data into a Pandas data frame and exploring the available fields. Note: I manually transformed the ‘embarked’ and ‘gender’ features in the csv before loading for brevity
Most elements seemed to be continuous and those that contained text seemed to be irrelevant to predicting survivors, so I created a new data frame (‘train_df’) to contain only the features I wanted to train on. Also, note that XGBoost will handle NaNs but (at least for me) does not handle strings.
Just like with other models, it’s important to break the data up into training and test data, which I did with SKLearn’s train_test_split. Note that I decided to go with only 10% test data. I did this primarily because the titanic set is already small and my training data set is already a subset of the total data set available. This is probably leading to a bit of overfitting and is likely not best practice.
With my data ready and my goal focused on classifying passengers as survivors or not, I imported the XGBClassifier from XGBoost. We then create an object for XGBClassifier() and pass it some parameters (not necessary, but I ended up wanting to try tweaking the model a bit manually). Finally we fit() the model to our training features and labels, and we’re ready to make predictions! As you can see, using the XGBoost library is very similar to using SKLearn.
![]()
Making predictions with my model and using accuracy as my measure, I can see that I achieved over 81% accuracy. This was after a bit of manual tweaking and although I was hoping for better results, it was still better than what I’ve achieved in the past with a decision tree on the same data.
One super cool module of XGBoost is plot_importance which provides you the f-score of each feature, showing that feature’s importance to the model. This is helpful for selecting features, not only for your XGB but also for any other similar model you may run on the data.
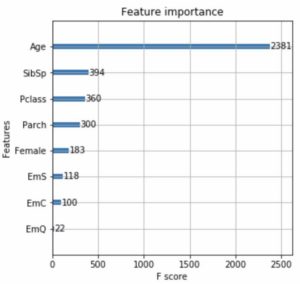
Taking this to the next level, I found a fantastic code sample and article about an automated way of evaluating the number of features to use, so I had to try it out.

Essentially this bit of code trains and tests the model by iteratively removing features by their importance, recording the model’s accuracy along the way. This allows you to easily remove features without simply using trial and error. Although not shown here, this approach can also be applied to other parameters (learning_rate, max_depth, etc) of the model to automatically try different tuning variables. I won’t go into the details of tuning the model, however, the great number of tuning parameters is one of the reasons XGBoost so popular.
I hope that this was a useful introduction into what XGBoost is and how to use it. Thanks for reading. Now, GO BUILD SOMETHING!
Helpful resources/references
GXBoost overview (essential read!)
Feature importance and selection
[ls_content_block slug=”contributor-article-disclaimer”]
