NOTE: This article assumes that you are familiar with a basic understanding of Machine Learning algorithms.
Suppose you want to buy a new mobile phone, will you walk directly to the first shop and purchase the mobile based on the advice of shopkeeper? No, right?
 You would visit some of the online mobile seller sites where you can see a variety of mobile phones, their specifications, features, and prices. You may also consider the reviews that people posted on the site. However, you probably might also ask your friends and colleagues for their opinions.
In short, you wouldn't take the decision directly but will instead consider the opinions of other people as well. Ensemble technique in Machine Learning works on a similar idea.
There are numerous ways by which you can achieve ensembling, which will be discussed in this article.
You would visit some of the online mobile seller sites where you can see a variety of mobile phones, their specifications, features, and prices. You may also consider the reviews that people posted on the site. However, you probably might also ask your friends and colleagues for their opinions.
In short, you wouldn't take the decision directly but will instead consider the opinions of other people as well. Ensemble technique in Machine Learning works on a similar idea.
There are numerous ways by which you can achieve ensembling, which will be discussed in this article.
Table of contents:
Introduction
Intuition
Bagging
An algorithm based on bagging: a. Random Forest Algorithm b. Hyperparameters in Random Forest c. Advantages and Disadvantages of Random Forest
Boosting
An algorithm based on boosting: a. AdaBoost (Adaptive Boosting) b. Gradient Boosting (GBM) c. XGBoost (extreme Gradient Boosting)
Stacking
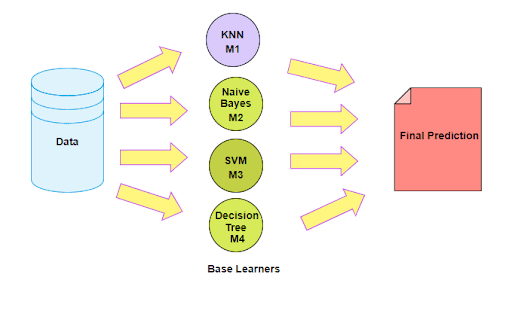
1. Introduction to Ensemble Learning
Ensemble learning is a machine learning technique in which several models are combined to build a more powerful model. The ensemble is primarily used to improve the performance of the model. That is why ensemble methods are used in various machine learning competitions such as KDD, kaggle, etc. and also used in real-world problems.

2. Intuition:
Let's understand the intuition behind the ensemble learning with the help of an example.
Suppose you have your own music club and you as a music producer created a very interesting song with the help of your team. You want to take ratings on the song after publishing it so that you can take care of those things next time.
What are the possible ways to take feedback?
 A. One way could be asking your family members to rate a song.
It is highly possible that the member that you have chosen from your family cares and loves you very much. He/she doesn't want to break your heart by providing negative ratings for the terrible song.
B. Another way could be asking another music producer.
This may provide a better idea of the song. Because of that person may be an expert in music and will provide appropriate ratings. On the other hand, if a person is a competitor then will not get proper ratings. So definitely it is not the best judge.
C. What if you asked 100 peoples to rate the song?
This 100 peoples can be your family members, colleagues, music producers, and others as well.
The ratings you will get will be more generalized because you have included all kinds of peoples with a different mindset. This is a better approach to get honest ratings than the previous 2 cases.
Well, Ensemble learning is no different than this: an ensemble is a method of combining diverse models to get more powerful, accurate and stable model.
Up till now, you have got a high-level idea of what ensemble learning is. Now let's look at the various ensemble techniques.
A. One way could be asking your family members to rate a song.
It is highly possible that the member that you have chosen from your family cares and loves you very much. He/she doesn't want to break your heart by providing negative ratings for the terrible song.
B. Another way could be asking another music producer.
This may provide a better idea of the song. Because of that person may be an expert in music and will provide appropriate ratings. On the other hand, if a person is a competitor then will not get proper ratings. So definitely it is not the best judge.
C. What if you asked 100 peoples to rate the song?
This 100 peoples can be your family members, colleagues, music producers, and others as well.
The ratings you will get will be more generalized because you have included all kinds of peoples with a different mindset. This is a better approach to get honest ratings than the previous 2 cases.
Well, Ensemble learning is no different than this: an ensemble is a method of combining diverse models to get more powerful, accurate and stable model.
Up till now, you have got a high-level idea of what ensemble learning is. Now let's look at the various ensemble techniques.
3. The Bagging Technique:
Bagging is a technique of combining the results from the various models to get the final predictions (maximum vote in classification and the average value in regression).
Here we are creating all the models on the same input data. Whether this will gives us a better result? There is a high chance that models will give the same result.
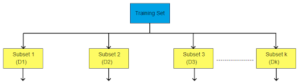
One of the solutions for this is bootstrapping.
Bootstrapping is a statistical method of estimating a quantity of data from original data. We create ‘k’ random samples with replacementfrom training dataset each of size d, where d < n and n is a number of training points.
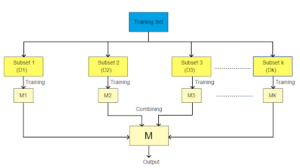
 After samples of subsets are formed, separate and independent models are trained with those subsets. The final predictions are made by combining the predictions from all the models to build the meta-classifier or regressor.
After samples of subsets are formed, separate and independent models are trained with those subsets. The final predictions are made by combining the predictions from all the models to build the meta-classifier or regressor.
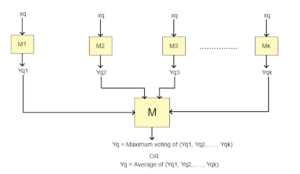
 For a given test point Xq
For a given test point Xq
4. An algorithm based on bagging:
4.1 Random Forest Algorithm:
Random forest is an implementation of the bagging technique. You can see from its name, it creates a forest of the decision trees from randomly sampled data and combines them. So base learners in the random forest are decision trees. You don't have to combine the decision trees instead you can use random forest classifier or regressor.
 If you don't know how the decision tree works, here's a guide to Decision Tree Learning.
So random forest is a collection of decision trees trained on different subsets.
Random forest guarantees randomness to the model by feature bagging. Feature bagging means we select not all the features the base learners but we randomly sampled some of the features to train the base learners. Now instead of searching for the most important feature while splitting at each node, it searches for the best feature among a randomly sampled subset of features. Therefore the model M1, M2,........., Mk will be even more diverse from each other results in better meta-classifier or regressor.
Hence for each base learner in the random forest, we do the following.
Random Forest = Row Sampling + Column Ampling
If you don't know how the decision tree works, here's a guide to Decision Tree Learning.
So random forest is a collection of decision trees trained on different subsets.
Random forest guarantees randomness to the model by feature bagging. Feature bagging means we select not all the features the base learners but we randomly sampled some of the features to train the base learners. Now instead of searching for the most important feature while splitting at each node, it searches for the best feature among a randomly sampled subset of features. Therefore the model M1, M2,........., Mk will be even more diverse from each other results in better meta-classifier or regressor.
Hence for each base learner in the random forest, we do the following.
Random Forest = Row Sampling + Column Ampling
4.2 Hyperparameters in Random Forest:
Here I will be discussing important hyperparameters in the random forest in sklearn.
n_estimators: It is a number of trees in the random forest before combining all of them.
max_features: It is used for feature bagging. The number of features to consider at each subset.
oob_score: Whether to use out of bag sample i.e. cv to estimate the generalization accuracy. Default it is False.
4.3 Advantages and Disadvantages of the Random Forest:
The default parameters of random forest often produce good results.
The major problem of overfitting will no longer happen in a random forest.
The disadvantage of a random forest comes when there is a large number of trees which increases the modeling time.
A more accurate prediction requires more trees, which results in a slower model.
5. Boosting:
In bagging, we assume that the base models will always give good results. But what if some of the data points are incorrectly classified? Combining such predictions will provide better results? Such scenarios are taken care of by boosting. Boosting is an iterative and sequential approach. It adaptively changes the distribution of training data after each iteration. Initially, all the data points are considered equally likely for random sampling. The model M1 is trained on the randomly sampled subset and errors are calculated. In the next iteration for incorrectly classified points, the probability of randomly selecting sampling will change from correctly classified points. The incorrectly classified points will be given more probability. So the model M2 will try to correct the mistakes made by the model M1. Therefore, the succeeding model is dependent on previous model results. In boosting all the base learners are weak and high bias models. It combines a number of weak learners to form a strong learner. Thus each weak learner boosts the performance of the ensemble.
6. An algorithm based on boosting:
6.1 AdaBoost (Adaptive Boosting):
AdaBoost is a popular ensemble technique based on boosting. Like boosting AdaBoost assigns a weight to each training examples, which determines the probability of each example appearing in training set. After training a model, AdaBoost increases the weight of misclassified points thereby giving more probability to appear them in next classifier and hopefully the next model performs well on that.
After each classifier is trained, the weights are assigned to each classifier based on their accuracy.
So the equation for the final classifier is: 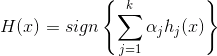 Hence the final classifier is just a linear combination of weak learners.
After training the first base model we calculate the weight (α) for that model as:
Hence the final classifier is just a linear combination of weak learners.
After training the first base model we calculate the weight (α) for that model as:
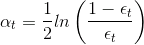
Where ∈t = No. of misclassification over that training set
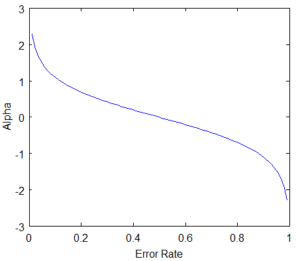 From the graph, we can see that the weights of the model grow exponentially as the error approaches zero. The weight becomes zero if the accuracy is 50% which is no better than any random guessing.
After calculating the α for the 1st model we update the training examples weights by the following formula.
From the graph, we can see that the weights of the model grow exponentially as the error approaches zero. The weight becomes zero if the accuracy is 50% which is no better than any random guessing.
After calculating the α for the 1st model we update the training examples weights by the following formula.
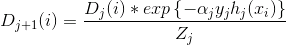

6.2 Gradient Boosting (GBM):
Gradient Boosting is a generalization of boosting to arbitrary any differentiable loss function. GBM is used for both classifications as well as regression. At each stage, the gradient boosting try to minimize the loss function. With the gradient boosting we can plug any of the loss function and that is the biggest advantage of it.
6.3 XGBoost (extreme Gradient Boosting):
XGBoost is an advanced implementation of the gradient boosting algorithm. XGBoost is a highly powerful algorithm that is used in may machine learning competitions and hackathons. It is faster than gradient boosting. But why XGBoost is so popular?
Parallel processing: Core XGBoost algorithm is parallelizable and it can use the power of multi-core computers. So it is feasible to train the model on large datasets as well.
Speed: XGBoost is originally written in C++ and it is comparatively faster than other ensemble techniques.
Variety of tuning parameters: XGBoost internally has parameters for missing values, tree pruning, regularization, missing values, cross-validation, etc.
Flexibility: XGBoost allows the user to define custom optimization objectives.
7. Stacking :
In stacking the base models are trained entirely on different algorithms. The main difference from the previous 2 ensemble techniques is the base learners are trained on the complete training set.



