Decision Tree is one of the most widely used supervised machine learning algorithm (a dataset which has been labeled) for inductive inference. Decision tree learning is a method for approximating discrete valued target functions in which the function which is learned during the training is represented by a decision tree. The learned tree can also be represented as nested if-else rule to improve human readability.
Table of contents:
Introduction
Intuition
ID3 Algorithm
Which attribute Is the best classifier?
Entropy
Information Gain
Information Gain Ratio
Decision tree for real-valued data
Decision tree regression
Bias-variance tradeoff
Avoiding overfitting in decision trees
Time and space complexity
Pros and cons of the decision tree
Introduction:
Decision tree learning is used for classification as well as regression is often called as classification tree and regression tree respectively. The term Classification And Regression Tree (CART) analysis is used to refer both the tasks. Decision tree learning is applied to a broad range of tasks from learning to diagnose medical cases to learning to access credit risk of loan applicants.
Intuition:
The decision tree algorithm works like a human brain every time we ask a question ourselves before making a certain decision. For example, it is discount offers are going on online shopping? If yes, then I will buy the products else I will not.
Throughout this article, we will be using a famous dataset in the machine learning world called as weather dataset. The dataset has 4 feature i.e. Day, Outlook, Humidity, Wind and one output variable y (yes or no) which is being categorical.

From this above 14 instances we need to learn the mapping between X and Y (which machine learning does always) and want to predict the whether the John will play tennis or not based on new feature vector (X)?
The decision tree takes the training set and split up it into the smaller subsets based on features. We repeat this procedure at every node of a tree with different subsets and attributes till there is no uncertainty that John will play or not?
When the new data point arises we just look in which of the subsets the points fall and classify a point to that class.
Let’s say we took Outlook attribute to split the dataset. The Outlook has 3 possible values i.e. Sunny, Overcast and Rain. So we split our dataset into 3 smaller subsets as shown below:

After splitting on Outlook attribute we have one pure node in which John always plays. So intuitively we can say that when Outlook is Overcast the John always plays.
On the other hand, we have 2 impure sets i.e. in those subsets we have no idea about John will play or not? For those subsets, the further splitting is required. Suppose for Sunny as an Outlook subset we took Humidity and splits further then the tree looks as follows :
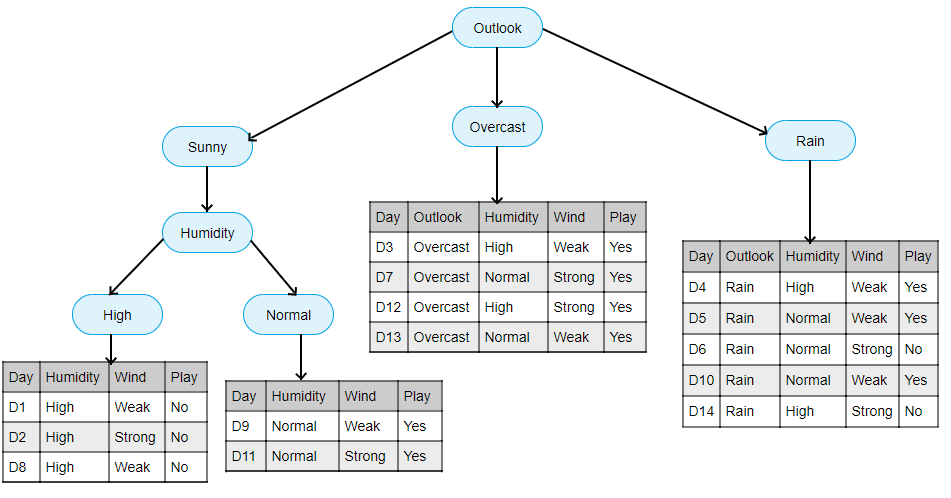
Now we have 2 pure and 1 impure subsets. When there is sunny outlook and high humid the John does not play and for normal humidity, the John plays.
For the rainy subset, we do further splitting based on Wind because it is not a pure subset.
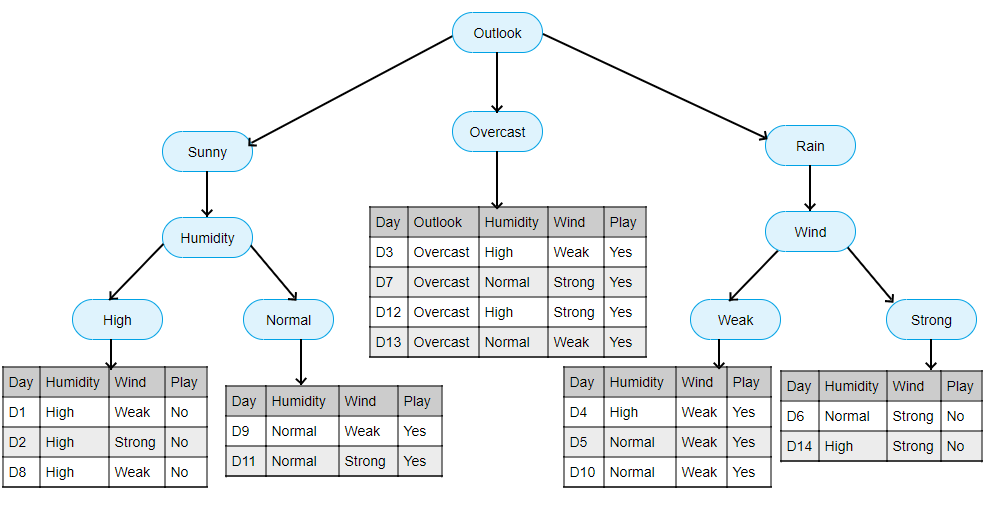
At this point, we have partitioned our entire training set into smaller subsets based on the small set of rules and each subset is pure i.e. in all subsets the John plays or not.
The final decision tree after replacing instances by labels will look like the following:

The dataset that we have discussed so far is an illustration of what the decision tree exactly produces as a data structure.
ID3 Algorithm:
ID3 (Iterative Dichotomiser) is a recursive algorithm invented by Ross Quinlan. The central choice in the ID3 algorithm is selecting which attribute to test at each node in the tree. We would like to select the attribute that is most useful for classifying examples. What is a good quantitative measure of the worth of an attribute? Later on, we will define a statistical property, called information gain, that measures how well a given attribute separates the training examples according to their target classification.
ID3 uses this information gain measure to select among the candidate attribute at each step while growing the tree.
Pseudo code for ID3 algorithm:
Parameters :
Examples: This is the training examples.
Target_Attribute: It is the attribute whose value is to be predicted by the tree.
Attributes: It is a list of other attributes that may be tested by the learned decision tree.
ID3 (Examples, Target_Attribute, Attributes)
{
Create a root node of the tree.
If all examples are positive, then return the single node tree root with a label as positive.
If all examples are negative, then return the single node tree root with a label as negative.
Otherwise, begin:
4.1. A ← The attribute from attributes that best classifies examples
4.2. For each possible values Vi in A
4.2.1. Add a new tree branch below the root, corresponding to test A = Vi
4.2.2. Let Vj be the subset of examples that have value Vi
4.2.3. If Vj is empty: Add new leaf node with a label as the most common value of Target_Attribute in Examples.
4.2.4. Else
ID3 (Vj, Target_Attribute, Attributes - {A})
Return root.
}
Which attribute Is the best classifier:
We could really pick any attribute to split into our training data which will result in different partitioning of the data. So how do we decide that one partitioning of data is better than other?
Let’s take original dataset where we get 9 yes and 5 no. Now we could either split o the Outlook or Humidity as shown below.
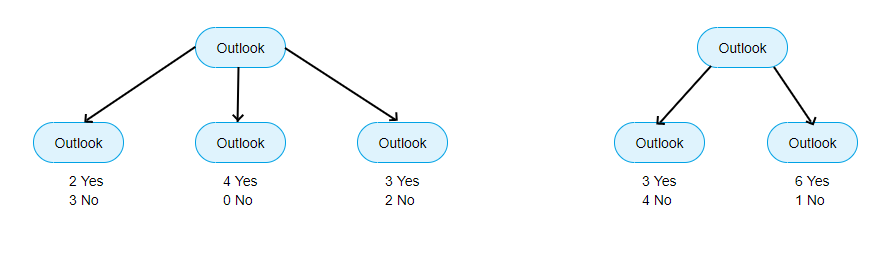
What is the difference between the above 2 splits?
If we split on Outlook we ended up with 3 subsets in which one of them is the pure subset. On the other hand, if we split it on Humidity will get 2 subsets in which none of them is pure.
Just by looking at above splits which split do you like better?
One can intuitively say that Outlook is better than Humidity because it has one pure subset.
If we are looking at 2 subsets of Humidity then intuitively normal is better than high even though it is not completely pure.
So what we want from decision tree are splits that give us subsets that are heavily biased either towards positive or negative class. Because the presence of lots of instances of any one class in that subset tells us what we are going to predict even though there are some points of class in that.
If we have perfectly balanced points in subset then we have no idea about what we are going to predict?
So we need some sort of measure to determine the purity of the subsets.
Entropy:
Entropy is the amount of uncertainty present in data. Before the split, we were quite uncertain about which points are positive and which points are negative. But after the split, we are more certain. If we have pure subset then we are completely certain on the other hand if we have 50-50% then we are completely uncertain about points in that split.
So intuitively we can say that entropy should be as small as possible.
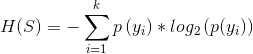
Where yi is an o/p variable which has ‘k’ possible cases.
Note that the entropy is calculated to specific subset so the p(yi) is the probability of yi that belongs to that particular subset, not the entire dataset.

Let yi∈{0,1}
Case 1: If we have 50% chances of 0 as well as 1.


Case 2: If we have completely pure set i.e. let say 4 yes and 0 no.

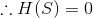
Information Gain:
The entropy is calculated just for one subset and for each node we have multiple subsets. So we are going to take the average of entropy for each of the subsets.

Where v = possible values of attribute A
S = Set of examples before split
Sv = subset where XA equal to v
“In simple terms information gain (IG) is the difference between entropies before the split and after the splits on possible values of A.”
We are multiplying the entropies after the split by the |Sv| / |S| where Sv is the number of possible values in attribute A and S is the number of values before the split.
By doing this we are giving higher weights to the subsets which are larger in size and lower weights to the subsets which are smaller. Because in smaller subset if we have only one instance then we are guaranteed that it is either belongs to one of the class but the case is not the same for bigger subsets.
Let's take weather dataset to illustrate the information gain.
We look Wind attribute as a root node to split our dataset. The calculation before and after the split on Wind is shown in below figure.

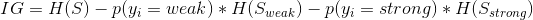
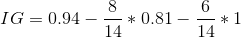

So 0.04 is the information gain on attribute Wind at the root node.
How do we use this gain to determine which attribute is better?
So we pick attribute with maximum IG. At the root node, we calculate IG for all the attribute and took one with the maximum value of IG. We repeat the same procedure for all the nodes except the attribute which are being selected previously.
Information Gain Ratio:
Information gain is a good measure but it has some flaws that we need to understand.
If we split our dataset on Day attribute then we ended with the singleton subsets. That is on each day the John will either play or not.

As far as IG is concerned day is the best attribute to split on. Because magically only on the single attribute splits into different subsets.
In general, there is some attribute which has lots and lots values which results into the very smaller subsets. This attribute is not generally good for testing.
So instead of IG, we could use IG ratio which is calculated as follows.

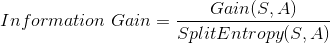
So, in short, we normalize the information gain by the split entropy.
Decision Tree for real-valued data:
Up until now, we have constructed a tree on an attribute which has categorical values. But what if we have continuously valued data?

So the decision tree for a real-valued attribute it picks some threshold based on that it will partition the data. So based on the condition of attribute we split the data. After splitting the data we repeat the same procedure of calculating information gain that we have done for categorical data.
The only extra work would be required is finding the all possible threshold which is very expensive. But if we pick right data structure to find threshold then it is not much expensive.
One interesting thing about real-valued data is that we may end up splitting one attribute more than one time.
Decision Tree Regression:
In regression the task instead of classifying point to one class we calculate the real value.
Unlike calculating the information gain we calculate the variance and try to minimize it. So we split data into multiple subsets based on attributes and took one with minimum variance.
While testing we reach the particular leaf node and took the average over all the points in that subsets and assign the average value to that testing point.
Bias-variance Tradeoff:
The depth of the tree is responsible for the bias-variance.
Up till now, we have split up data till we get pure node. If we look at the accuracy graph as a function of the size of the tree will look like as follows.
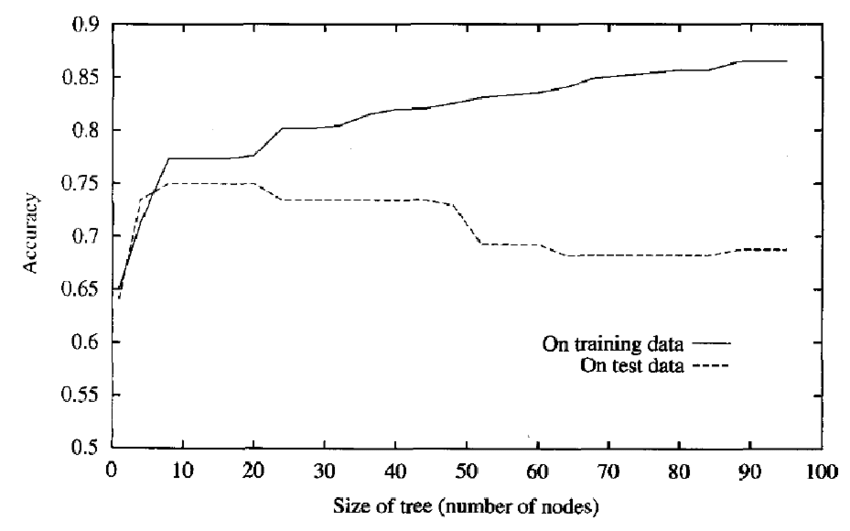
We can clearly see that the model is performing well on training data but on test data the accuracy suddenly drops to smaller values. So in this, we might overfit.
If the depth of the tree is too small then we might underfit.
Avoiding overfitting in decision tree:
To avoid overfitting in DT means to stop the growing tree further before it becomes too specific to training data. There are 2 methods to avoid overfitting in DT :
Pre-Pruning
Post-Pruning
1 Pre-Pruning: In pre-pruning, it stops the construction of tree bit early. It stops splitting node if its goodness measure ie below a threshold value. But it is quite infeasible to choose the appropriate threshold value.
Post-Pruning: In post-pruning, we take training data and divide it into 2 parts. Hide the one part of data completely from the algorithm that we called as cross-validation and train a full decision tree until we get leaf nodes.
Now take out validation set and test on the learned tree which will not give 100% accuracy because the model has overfitted. After this for each non-leaf node in the tree, we temporarily prune the node and replace it by majority class. Again test the validation set on the pruned tree we get another accuracy. Repeat the same procedure for each non-leaf node and record the validation accuracy and took one pruned tree which will give the highest accuracy on validation data.
Pseudocode :
1.Partition the train data into 2 parts.
Build the complete tree on train data.
Until accuracy on cross-validation increases do
{
for each non-leaf node
Temporarily prune it and replace by majority vote.
Test the accuracy of the model on CV data.
Permanently prune the node with the greatest accuracy on the CV. }
Time and Space complexity:
Training phase :
T (n) = O (nlogn * m)
Where m = number of features
Testing phase:
S (n) = script of nested if-else condition
∴ S (n) = O (Total nodes)
T (n) = O (Depth)
Pros and Cons of the decision tree:
Pros:
DT is a sequence of if-else which is highly interpretable to humans.
It handles the irrelevant attributes easily.
DT automatically does the multiclass classification.
Once the DT is built it becomes very fast at the testing time.
DT’s are very compact.
Cons:
The decision tree may not find always the best tree because it uses the greedy approach to build the tree.
For every large dimensional data, the training time is high.
DT only forms axis parallel hyperplanes for a real-valued attribute.



