This research article helps readers who are doing research under Adaptive E-learning and Personalised Learning. Generally, in developing e-learning systems, many challenges still exist from the perspectives of assisting the end users, facilitating the learning process and enhancing the learning outcomes. This article presents an approach to dynamically compose the adaptive e-learning courses based on the learner activities, learning objectives and instructional design strategies using Reinforcement Learning technique thus attempting to adapt to the learner, learning and instructor requirements. In addition, Instructional Design policies were applied here while designing dynamic course modules.
RL Agent for Learning Course Composition
The Reinforcement Learning (RL) technique learns the behaviour of the learners automatically and provides the course materials needed to achieve the learning objectives based on the positive and/or negative feedback of the learners. In this work, learners can browse through the e-learning system, select the course, learn lessons, practice exercises, do assignments, and answer assessments. The e-learning system keeps track of the students’ navigation log files. Our e-learning system acts as an intelligent agent here. It senses the various learner interactions, and chooses the best possible reactions of the learner, so as to enhance the learning experience of the learner. If the same learner uses the e-learning system again, then the previously learned options observed by our RL agent, provide the best learning content in the same manner as the previous time. Reinforcement learning scenarios (Q-learning) are described by states, actions, and rewards (positive/negative).
*Q-learning algorithm (Watkins, 1989): Q-learning is a form of model-free reinforcement learning (Watkins & Dayan, 1992). The problem domain (e-learning) consists of agents, its various states S, a set of actions for each state A, and transitions (agent can move from one state to another by performing some action a*). The transitions (next state) give a reward to the agent. The goal of the agent is achieved by optimizing the actions for each state to maximize the total reward. Hence, the Q-function calculates the excellence of each state-action combination. Initially, the Q-function returns a fixed value, set while designing the algorithm. Then, during each transition when the agent is rewarded, new values computed, and the Q-table is updated. The Q-function we use here is,
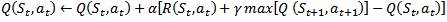
t
– Current state
t+1
– Next state
Q
(St, at) – the Q-values for the current state
R
(St, at) – Reward obtained for performing the action at
in St
α
– Learning rate (0 ≤ α ≤1)
γ – the Discount factor which decides the significance of the future rewards (0 ≤ α ≤1)
Q-learning is called as an ‘off-policy' or
policy independent algorithm, as it does not depend on any policy. The policy
is the decision process, which is used to select an action for a given state.
Q-learning works on the greedy mechanism and selects the maximum of the
Q-values of the state-action pairs, which are possible from the present state.
The agent learns through experience through exploration. Each exploration is
called an episode (Sutton & Barto, 1998).
In Q-learning, if the discount factor (γ) value is set to 0, γ = 0: it means the updating can happen without considering the new state.
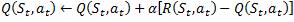
a. If the learning rate (α) value is set to 0, α = 0: it means no learning takes place, and the Q-value remains as it is.
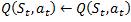
b. If the learning rate (α) value is set to 1, α = 1: it means the agent will consider only the most recent information, which is only the reward.
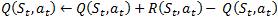
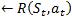
c. If the learning rate α = 0.5, the old and the new Q-values meet halfway, given the reward.
Therefore, the discount factor γ is 0; the agent will consider only the current reward.
If the discount factor γ = 1, α = 1 then, it means that the updated Q value for a state is equal to the reward plus the maximum of the possible Q values from the state.
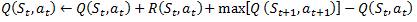
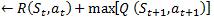
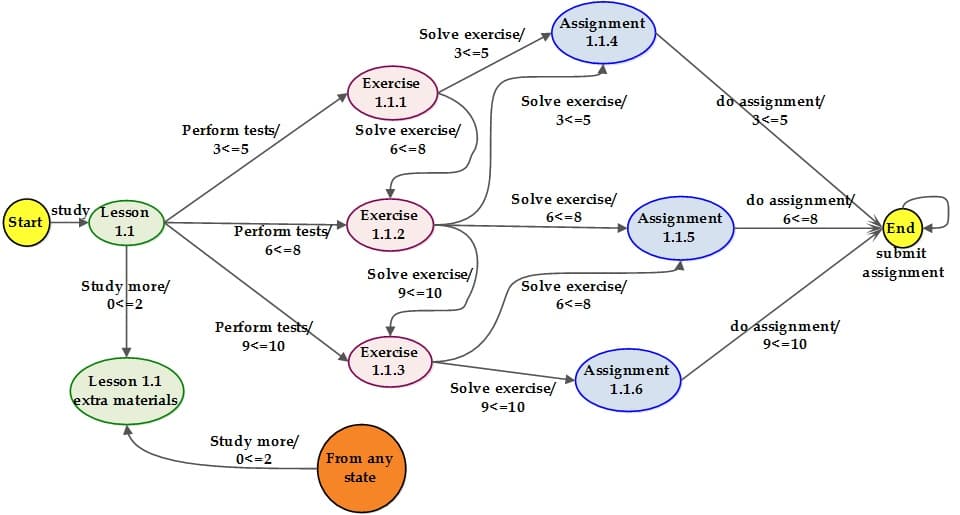
Figure 1 shows the learning modules for a single lesson under the topic ‘Linear data structures’
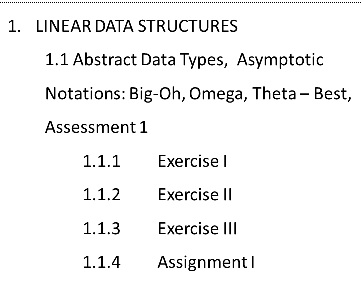
In this
work, the possible states are the learning modules such as lessons, exercises,
assignments, and assessments. The actions are study, study extra material,
solve exercises, perform tests, submit assignments, and exit from the
system/course. The rewards we define as ‘rating' from the range of 0 to 10. If
the learner takes the rating of (3<=5) in the test performance in the
lessons, then he/she will be provided with a low level of exercises (learning
module). If the rating is (6<=8), then a medium level of exercises will be
provided. If the rating is (9<=10), then a high level of exercises will be
provided. If the learner takes (0<=2) rating, he/she needs to study extra
learning materials which are provided by the RL agent. Likewise, we configure
and provide assignments at low, medium and high levels. Figure 2 shows the
various states, transitions and their rewards with respect to the
above-mentioned ratings for all learning modules (nodes) in a single
lesson.
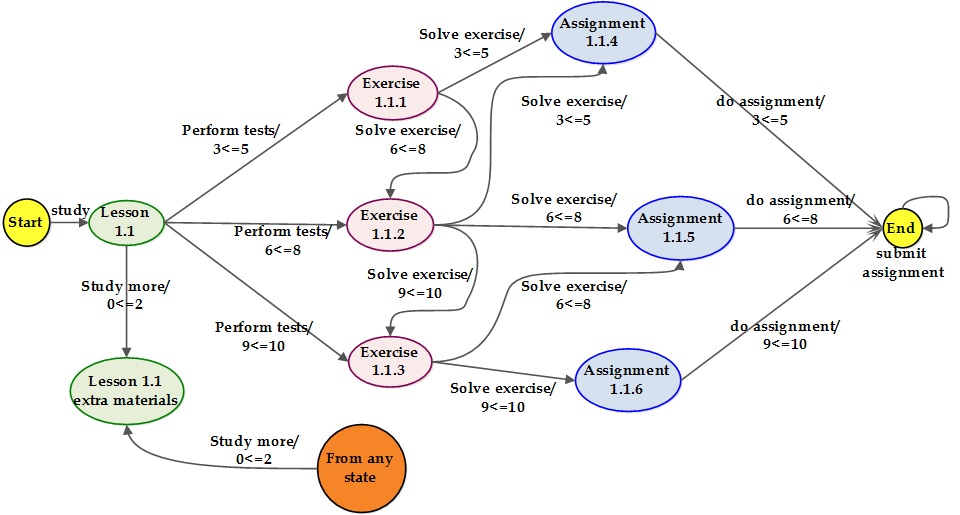
Once the early stage (initial episode) is over, the system learns the best action to be considered for getting the maximum reward. In all future interactions, the system chooses the best learning path based on the reward table values and continues the execution. However, in our system, it is also possible for the learners to choose their own path (deviate from their previous path) by doing some new actions. In this situation, the reward table obtains new values and updated completely.
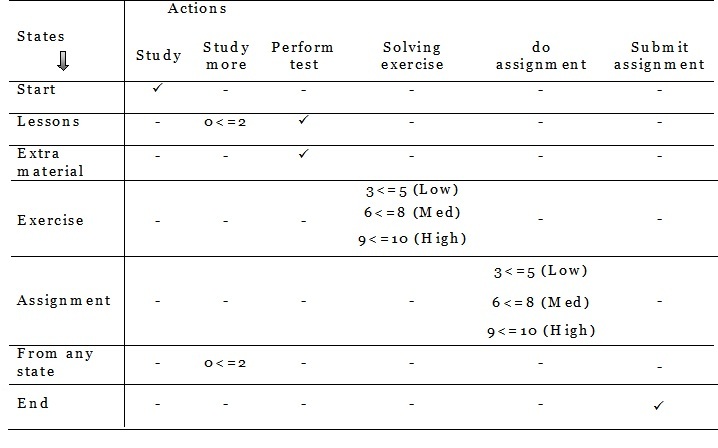
Sample Reward table for states and their corresponding actions
Instructional Design for Dynamic Course Composition
Instructional Design is the art
of building an instructional environment and resources. Instructional Design is
based on theoretical and practical research in the fields of cognition,
educational psychology, and problem-solving. The importance of instructional
strategies is the creation of the best practices' guidelines for all aspects of
the instructional process, namely, planning and management of online
instruction, teaching techniques, student assessment, and evaluation
techniques. The ID is the initial concept you must understand, to create
successful course plans in e-learning. The theory is that learning produces
measurable or demonstrable changes in learners' thinking skills, physical
capabilities, or attitudes. Hence, lessons can be constructed to reach one or
more specific learning objectives. Course plans, then, are created from an
organized set of specific learning objectives.
Alonso et al (2005) proposed an instructional model which is based on the systematic
development of instruction and learning, and is composed of seven phases:
analysis, design, development, implementation, execution, evaluation, and
review. The model includes a series of psycho-pedagogical prescriptions that
describe the learning process. There are a number of different
instructional design models. ADDIE is a famous one. In e-learning,
instructional design is usually associated with the ADDIE model, which
describes the process for entire courses. The author also stated that
e-learning is sometimes seen as a sub-set of instructional design, and is a
partnership between pedagogy and digital technology.
In this research, we follow the Dick and Carey ID model while designing the dynamic courses. This model generally follows the ADDIE concept, but it provides task-specific process steps at each stage. Gustafson and Branch (2001) have described the taxonomy of models as being classroom-oriented, product-oriented, and systems-oriented. Classroom-oriented models generally have an output of a few hours of instruction on courses. It assumes an instructor, students, a classroom, and a piece of instruction that needs to be enhanced. Product-oriented models have an output of an instructional package and focus on making production more efficient. Finally, systems-oriented models have an output of a course or curriculum. It aims to provide a complete instructional system for managing learning needs (Prestera, 2002).
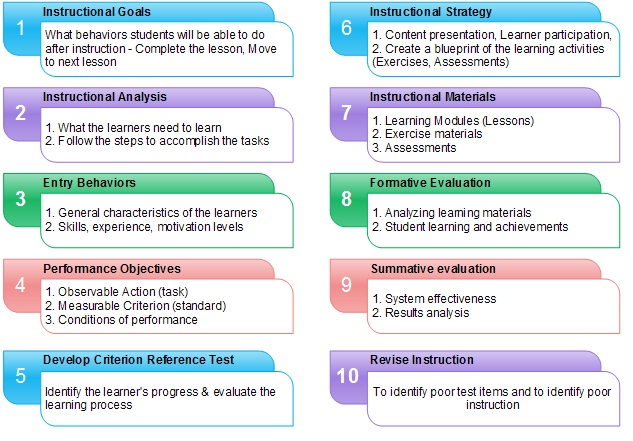
In this work, we use the systems-oriented (Dick and Carey), model. It is an iterative process that is applicable across a range of content areas. This model is perhaps the most well-known of the systematic design models and is the standard on which all other ID models are based on (Gustafson and Branch, 2002). The model views instruction as a systematic process in which all components (i.e. teacher, students, materials, and learning environment) are essential to successful learning. All system components rely on each other for input and output. The whole system uses feedback to determine if its desired goal has been reached (Dick and Carey, 1990). While designing the learning courses, we perform the following steps of the Dick and Carey model, (i) Define Instructional goals, (ii) Perform Instructional analysis, (iii) Define Entry behaviors and learner characteristics, (iv) Outline Performance objectives, (v) Create tests and evaluations to ensure the learners’ necessary prerequisites, identify the learners’ progress and evaluate the learning process, (vi) Create a blueprint of the learning activities that will transfer, develop, and reinforce the skills and knowledge formulated in the performance objectives, (vii) Gather Instructional Materials, (viii) Perform Formative evaluation (analyzing learning materials, student learning and achievements), and (ix) Perform Summative evaluation (system effectiveness and results analysis). Figure 3 shows the instructional design steps which we follow while designing the learning courses.
Conclusion
This research
article presented a dynamic learning content selection mechanism for learners
to obtain their suitable learning content every time and composed the learning
courses dynamically for adaptive e-learning, using Reinforcement Learning
technique. In addition, we followed instructional design policies while
composing the learning courses.



