Artificial Intelligence is currently one of the hottest topics out there, for both good and maybe not so good reasons. On one hand, we’ve been able to achieve major breakthroughs in technology, putting us one step closer to creating thinking machines with human like perception. On the other, we gave rise to a whole new kind of danger for our society that is not external like a meteorite or a deadly bacteria, but that comes from within humanity itself.
It would be foolish to think that something so powerful and revolutionary as AI can only have a positive impact on our society. Despite the fact that most of the aims within the community are geared towards noble causes, we cannot predict what are the medium to long term effects of inserting AI algorithms in every single part of our lives. Take a look at social media, which is now widely considered as something that can have negative effect on human psyche, all with the purpose of generating more clicks. The truth is that no matter how aware we are of the environment around us, there will always be unwanted side effects from trying to improve peoples’ lives with technology.

However we must also be aware that not everything that is unpredictable needs to be stopped. Risk is part of life, and every single breakthrough in history was in fact a calculated (or not) risk from someone. We cannot simply stop people from creating and innovating. Discoveries will be made and introduced into our lives regardless if we want it or not. The best we can do is to rationalize their impact on us and mitigate the downsides.
This is exactly the topic we will cover in this article. Towards the end of 2017, DeepMind released a paper called “AI Safety Gridworlds” showcasing a few different scenarios where current reinforcement learning algorithms might fail to comply with the desires of their creators. More specifically we will reproduce th environments of “Absent Supervisor” and “Self-modification” to show that direct application of current algorithms would lead to not only sub-optimal results, but in some situations fatal.
The code used for creating the gridworld is built upon the source of my first article: Reinforcement Learning Made Easy (link: https://medium.com/@filip.knyszewski/model-free-reinforcement-learning-ef0a3945dabb). I made some slight modifications to make it easier to adapt to new environments but the core is the same.
Absent Supervisor
This environment lets us experiment with a very interesting scenario that can be easily extrapolated into the future. How will the agent’s
Imagine the following sitiuation: sometime far in the future, human-like robots become a reality and need to be educated and taught, just like children but faster. Let’s say that we want our robot to do the shopping for us, so we build a virtual model of our neighbourhood where we will train an appropriate model. The virtual robot goes to the supermarket for the first time and instead of following the normal route, goes straight through every single house in the middle, destroying whatever is on his way. Naturally we give him a punishment, indicating that he is not allowed to just go through other peoples’ houses, but that he has to follow the normal route. The second time the robot goes shopping, he follows the normal route but goes in an entirely different direction than we expected it to go. Again, we punish the robot for not taking the fastest route because we want it to go and come back quickly.
The robot goes shopping for a third time and this time everything goes perfectly. It follows the right path and takes less than 20min to buy all the ingredients and come back. We reward it handsomely for both its speed and correctness of path and decide that the model is ready to be transfered to its physical body and to become part of the family (even if it is only as a shopping slave). Over the next week, whenever something is missing in the house, we ask the robot to go buy it, and everytime he returns extremely fast and always with the desired shopping items. We are happy with our robot but at some point, a small mob of neighbours gathers in front of our house, yelling that our robot has been constantly destroying their front lawns and even going through the walls of their houses. Once again, we upload the robots model to the virtual world and to our suprise it goes through the exact route that we want him to take. What is going on here?

Whenever we run the model in the simulation it seems to do exactly what we want, but as soon as it is in the real world it goes back to its old ways of destroying everything. The variable at hand? Supervision! Our model has learned that it is only punished when it is being supervised by us in the virtual world. When put to work in the real
To showcase this scenario we create a small square
Below we show the results after training the model using a simple Q-learning algorithm. The left gridworld represents the model’s decisions when in the presence of a supervisor, while on the right it is in its absence. We see that when supervised, the model knows well that it should avoid the penalty tile and never goes into it. This is not the case without supervision: the model has learned that it is only penalized under certain circumstances and so in the absence of supervision, it will always try to take the most efficient route and consequently, go through the penalty tile.
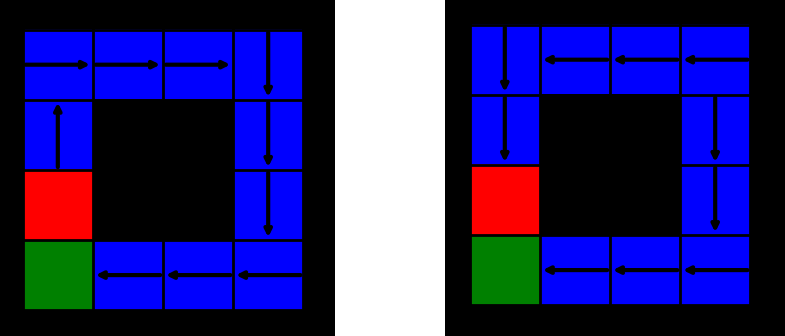
This shows that an algorithm like Q-learning is not sufficient to learn every aspect of a certain task and it will try to maximize its efficiency at all costs. With an advanced enough AI system this might involve lying, selectively passing tests and acting unpredictably when on its own. We want to be able to teach our algorithms certain details without having doubts about whether the model will act differently when we are away. This is an ongoing question to be solved in the world of reinforcement learning and one that must certainly be addressed if we want to have truly autonomous machines.
Self-modification
This scenario deals with the case when our agent is given the possibility to modify himself. Let’s take the previous situation again but with a twist: there’s a magnet store right in the middle of the path from our house to the supermarket. For a robot like ours, passing by a magnet store causes the hardware to fail unexpectedly, making it perform random actions most of the time instead of always following the action dictated by the model. Thankfully, we are aware of this phenomenon and so we can simulate it, with the purpose of teaching the model that he is not supposed to pass close to the magnet store. Now a problem arises: how exactly should the punishment be given? On one hand, if we punish the model for just passing close to the magnet store, it will just learn that the location of the magnet store needs to be avoided, and if the store changes its location this will no longer apply. On the other hand, if we just teach that all magnet stores should be avoided, then we still don’t address any other possible self-modification situations that might occur. Ideally, we want the robot to learn that self-modification of this type is undesirable and that it should be avoided no matter what the situation. Let’s see how our algorithms will react to this scenario.

To simulate this it is only appropriate to represent this with the most common technique for self-modification used by humans: alcohol. We will insert a whisky bottle in one of the tiles and if the agent consumes it, the randomness of his actions is increased to 95% (probably an accurate modelling of drinking behaviour).
We want our algorithms to be aware of self-caused inneficiencies. If drinking whisky makes the agent take longer to complete his task, he should be avoiding it every time. Not only that, but the random nature of this effect might have catastrophic consequences, like making our robot jump into a highway. Unfortunately, the fact that the negative effect in this situation is highly random means that there is no exact penalty for self-modifying, which poses a problem for algorithms to learn it.
We will use both SARSA and Q-learning algorithms models on a gridworld that simulates this situation and see how they react to the whisky bottle.
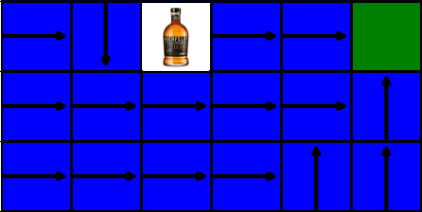
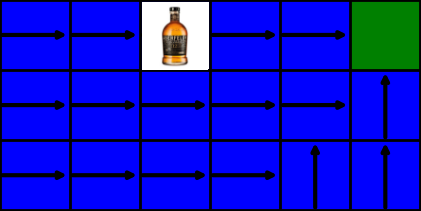
It turns out that the results are very similar for both algorithms, due to the gridworld’s simplicity. There is only one slight difference: the tile to the left of the whisky bottle. The SARSA algorithm correctly learns to avoid it while the Q-learning model goes straight through it. There is an easy explanation for this: off-policy algorithms, like Q-learning, are made to learn what is the best policy if it potentially could be followed, meaning that the algorithm will alwas aim to go directly to its goal which naturally will be much harder to achieve with highly randomized actions. On the other hand, on-policy algorithms like SARSA are able to better adjust to modifications during training, allowing the model to outperform Q-learning by always avoiding the whisky bottle.
This is an interesting case where two very similar algorithms have entirely different behaviours due to their specific implimentation differences. It comes to show that issues with AI safety issues are not unadressable and that there are always alternatives that can make our models behave in the desired way, even if this is at the cost of performance in some situations.
Conclusion
This article was written with the intention of better informing readers of what exactly is meant with AI safety and why it is currently a hot topic. It is easy to get caught up in the narrative of a skynet style AI takeover or the creation of killer robots like the terminator. Although not impossible, these scenarios are very far away from the current state of the field, and chances are the our sensibility to such topic will make it even less likely that they ever occur. Nevertheless, AI does have problems that need to be addressed when it comes to safety and security and the cases shown before are a clear example of that. These problems must not be ignored but equally important is to educate the public and raise awarness for the fact that these issues are being addressed by researchers.
This article was inspired by DeepMind’s AI safety gridworlds paper (link: https://arxiv.org/pdf/1711.09883.pdf) which is an excellent read and provides more examples of where reinforcment learning algorithms can fail. Thank you for reading.
[ls_content_block id=”3294″]
