
Abhishek Thakur is the first person in the world to have achieved the rank of Kaggle Triple Grandmaster.
Kaggle is the world’s largest online community of data scientists and machine learning engineers, where they can work together and enter competitions to solve data science challenges.
Abhishek Thakur also serves as the Chief Data Scientist at boost.ai, a software company that specializes in conversational artificial intelligence (AI).
In the first part of the interview, Abhishek shares his journey from getting into data science to becoming Kaggle Triple GM, the challenges he overcame, as well as his advice to aspiring data scientists.
In the second part of the interview, Abhishek discusses his work at boost.ai and provides thought leadership on Conversational AI.
You are the first person in the world to have reached the level of Kaggle Triple Grandmaster. What does this achievement mean to you?
It is indeed a very difficult achievement to get. There are over 150K active members and it took 3 years for someone to get the title of triple grandmaster so it feels quite good. I’m very happy about it.
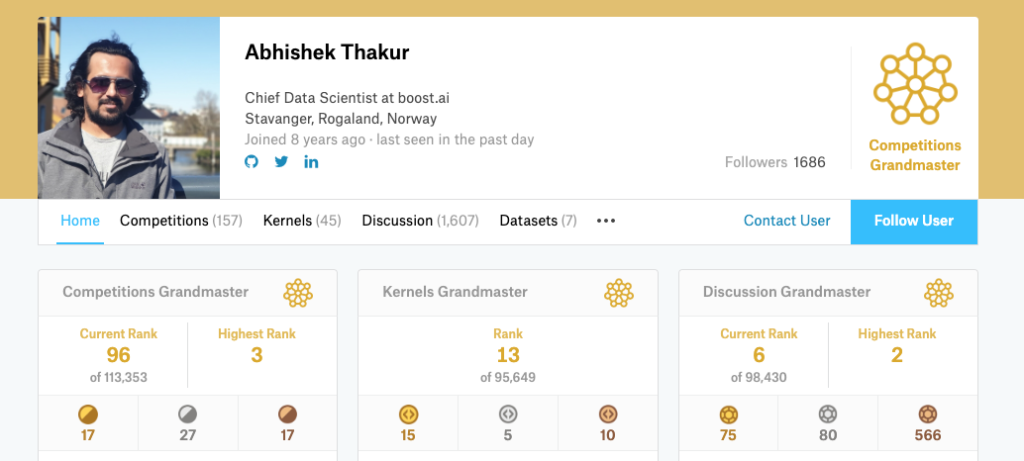
How did you achieve this milestone?
Achieving this milestone required a lot of hard work, dedication, and persistence over a period of 6 years. Every challenge brings something new to learn with it. If there is something in the data that you have less knowledge about or don’t know about, it can become challenging and the only way to avoid it in the future is to learn how to approach different problems and datasets and that can only be accomplished by practicing.
Achieving this milestone required a lot of hard work, dedication, and persistence over a period of 6 years. Every challenge brings something new to learn with it.
How did you get into data science? What challenges have you overcome along the way?
I come from an Electronics Engineering background but I always had an interest in Computer Science. So, I came to Germany from India to study a Master in Computer Science. During my Master’s degree, I was working with Fraunhofer as a student where I was building image processing algorithms for microcontrollers. At the same time, my friends were working on Natural Language Processing and I was always fascinated by their talks on natural language processing and neural networks. I took a machine learning course at the university but it seemed like it was not made for me. So, I started reading on my own and picked up a problem about emotion recognition on Kaggle. I used very basic approaches and failed badly in that competition. I waited till the winners shared their approaches, read them and implemented them. I read quite a lot of papers and implemented a few on my own during the time I was a student. Rather than taking a course I decided to learn everything on my own instead and by application. So, I would choose a problem and try to solve it and during that course, I would come across a lot of things I wouldn’t know. So, I would search for them online and try to understand it by reading papers or watching youtube lectures.
What data science tools and technologies do you primarily use?
I use python. Some of the libraries that I use very often (almost every day) are scikit-learn, pandas, xgboost, Keras, TensorFlow and PyTorch.
What are the key skills that a data scientist should possess?
A data scientist should have some mathematical background, for example, basic algebra, calculus, and knowledge of probabilities.
In addition to that, the most important thing is the ability to think out of the box and try to start solving a problem in a stepwise manner. A good data scientist should try to solve the problem in a way which is most effective and useful to the industry and consumers.
Programming is also something that is required and is a must-have for data scientists. One can not be a good data scientist if they don’t know how to implement the algorithms on their own or how to make the algorithms useful, faster and scalable.
What is your advice to people who want to become data scientists?
To start with I can recommend Andrew Ng’s courses on Coursera. He explains everything in the simplest manner possible.
Many people who want to change their field to data science these days or many students who want to enter the field of data science lack one basic thing: building a portfolio. You can read as much as you want, you can do online MOOC courses but in the end, if you don’t know how a machine learning problem can be approached, you will have a lot of trouble getting into a good industry.
To start with a problem, I suggest taking up an ongoing competition on Kaggle and try to solve it by yourself. One can also take a look at kernels and discussions for a quick start and if they are stuck. Even if you don’t get a good rank in the competition, in the end, don’t give up! This is also something I have seen quite often that people tend to give up quite early. If you have not performed well in that competition, take a look at the winner’s solution and try to understand and implement them on your own. One should never feel intimidated by others and give up, ever.
Once you have hold of some machine learning problems that you have solved or tried to solve yourself, you should write a short article about it either in Kaggle discussions or anywhere else and share the code in a proper format via Github. These two things will take care of your understanding of the problem and coding skills.
Last but not least, you need a lot of dedication. A few hours every day if you are a student. If you are working maybe 1-2 hours a day. You can obviously invest a few more hours over the weekends. Rather than investing time, it’s more about understanding a given problem statement and write down the different approaches you want to try.
What are your future objectives as a data scientist?
My future objectives are to keep learning and contribute to the community. I do not have a defined objective but I just want to keep contributing and share with the data science community and help people who are fascinated by this field and are working hard to get into the field of data science.
Conversational AI Q&A
This interview has been featured in the Conversational AI Initiative 2019.
![]()
How do you leverage Conversational AI at boost.ai?
Our conversational AI solution is unique in the market. It offers a far greater level of understanding than typical chatbots thanks to our proprietary Automatic Semantic Understanding. This allows virtual agents built on our technology to handle incredibly complex customer requests, accurately deal with multiple intents at the same time and reduce the likelihood of false positives by up to 90% in some cases.
How can companies leverage Conversational AI to make their customers happier and more satisfied?
Our strategy at boost.ai is to help our clients always put customer experience first. We do this, firstly, with what I’ve already mentioned – next-level language understanding. But we also recognise that a virtual agent isn’t going to get things right one hundred percent of the time. Therefore, our solution is designed to identify when it is more appropriate for a human operator to be brought into the mix. Conversational AI can do what it does best – automate interactions at scale. For anything more nuanced, it allows for a smooth handover to a human operator so that customers get a frictionless experience every time they interact with a brand, whether it’s with a human or a machine.
Which Conversational AI-related technology trend do you think will have the biggest impact in your industry in the coming years?
I think one of the biggest trends in conversational AI will be a marked shift away from the informational nature of the technology into a more transactional capacity. We are already seeing this happening in 2019, with banks, insurance companies and telcos using their virtual agents to carry out procedures on behalf of customers. Right now it’s possible to do things like reset PIN numbers and transfer funds via a virtual agent without a human operator being involved. In the not-too-distant-future, we can expect them to be able to go one step further and take on advisory roles, helping customers with choosing a pension plan or giving advice on mortgages.
I think one of the biggest trends in conversational AI will be a marked shift away from the informational nature of the technology into a more transactional capacity.
